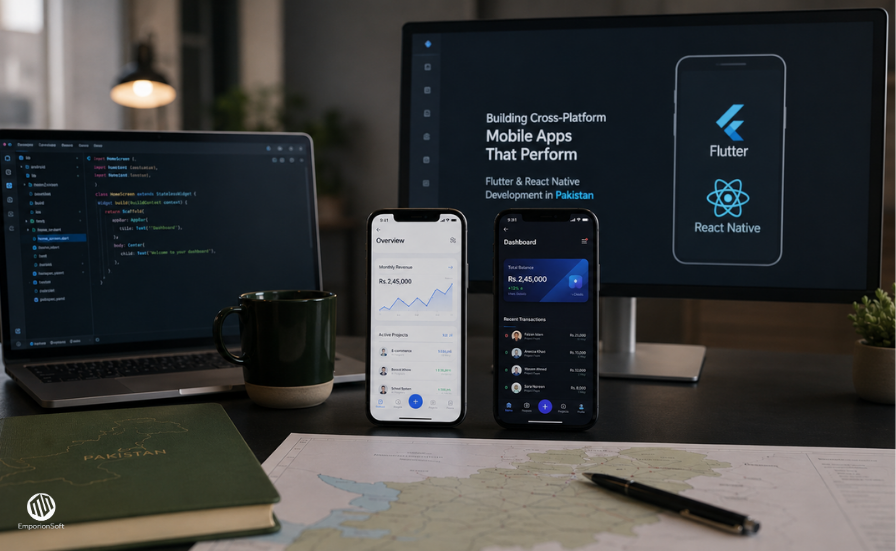
Why Growing Businesses Are Rethinking Their Data Foundations
For many growing businesses, data strategy was never a first order decision. Early systems were built to support reporting, compliance, or a small set of operational dashboards. As long as revenue was growing and teams were aligned, the underlying data foundations rarely came under scrutiny.
That has changed. As startups scale and SMEs expand across products, channels, and geographies, data volume and variety increase faster than organisational maturity. Transactional systems are joined by product telemetry, customer behaviour data, third party integrations, and increasingly unstructured sources such as logs, events, and documents. What once fit neatly into a reporting database now stretches beyond its original design assumptions.
This shift is why the question of data lakes vs data warehouses has become central for growing businesses. The debate is not academic. It is a practical response to new analytical demands that traditional setups struggle to support.
One driver is the move from descriptive reporting to exploratory analysis. Founders and product leaders want to ask new questions without waiting weeks for schema changes or pipeline rework. Marketing teams expect near real time insights. Engineering teams need access to raw operational data to diagnose performance issues. These needs expose the limitations of rigid data models and tightly controlled ingestion processes.
Another factor is cost sensitivity. Growth stage organisations operate under tighter margins than large enterprises. Cloud platforms have lowered the barrier to entry, but inefficient architectures can still create runaway storage and compute costs. Choosing the wrong data foundation can lock a business into expensive patterns that are hard to unwind later. This is why many teams are reassessing how structured and unstructured data storage choices affect both flexibility and long term spend.
Artificial intelligence and advanced analytics add further pressure. Even teams that are not building machine learning products today are laying the groundwork for future capabilities. Training models, running experiments, or supporting real time analytics often requires access to raw, high volume data. Traditional business intelligence platforms were not designed with these workloads in mind, which pushes teams to explore alternatives.
There is also an organisational dimension. As companies grow, data ownership becomes fragmented. Different teams generate and consume data in different ways. Centralised reporting teams struggle to keep up, while decentralised approaches introduce governance and quality risks. The underlying data architecture plays a significant role in how these tensions are resolved.
Importantly, this is not about replacing one system with another. Many businesses already operate a mix of tools and platforms, often without a clear strategy. The challenge is to understand what role each component should play and how it supports current and future decision making. A thoughtful comparison of data lake vs data warehouse approaches helps clarify these roles.
At EmporionSoft, this reassessment often emerges during broader conversations about scaling technology foundations and aligning systems with business goals. Our work with growing teams consistently shows that data architecture decisions have ripple effects across engineering velocity, analytical capability, and operational resilience. This is why data foundations deserve the same level of strategic attention as application architecture or cloud strategy, as explored in our wider insights on scalable technology planning at EmporionSoft Insights and our service approach to data and cloud solutions.
As industry research highlights, modern data platforms are evolving to support a wider range of analytical workloads without forcing early optimisation, a trend outlined in Google Cloud’s overview of data lakes. For growing businesses, understanding these shifts is the first step toward making informed, sustainable choices about their data future.
What Is a Data Lake and What Is a Data Warehouse
To make sense of the data lakes vs data warehouses discussion, it helps to step back from tools and vendors and focus on first principles. Both approaches aim to make data usable for analysis and decision making, but they are built on very different assumptions about structure, control, and change.
A data warehouse is designed around structured data and predefined questions. Data is extracted from source systems, transformed into a consistent format, and loaded into a central repository. This process, often referred to as ETL, enforces schema on write. The structure of the data is defined before it is stored, which makes querying fast, predictable, and well suited to business intelligence workloads.
This model works well when data sources are stable and reporting requirements are clearly understood. Finance reporting, sales performance dashboards, and operational KPIs all benefit from the consistency and governance a warehouse provides. Many organisations adopt this pattern early, sometimes without realising it, by building reporting layers on top of relational databases or managed warehouse platforms. A broader discussion of structured data design trade offs can be found in EmporionSoft’s analysis of SQL vs NoSQL databases.
A data lake takes a different approach. Instead of enforcing structure upfront, it stores data in its raw or lightly processed form. This includes structured tables, semi structured formats like JSON, and fully unstructured data such as logs or media files. The defining principle is schema on read. Structure is applied only when the data is queried or processed for a specific use case.
This flexibility makes data lakes attractive for exploratory analysis, big data analytics, and machine learning workloads. Teams can ingest new data sources quickly without redesigning schemas or pipelines. Engineers and data scientists can work directly with raw data, which preserves information that might otherwise be lost during transformation. The underlying mechanics of this approach are well summarised in AWS’s explanation of how data lakes work.
However, flexibility comes with trade offs. Without strong discipline, data lakes can become difficult to navigate, leading to inconsistent definitions and quality issues. This is why many early data lake implementations struggled to deliver value, despite their technical promise.
From an architectural perspective, data warehouses prioritise reliability and performance for known queries. Data lakes prioritise adaptability and scale for unknown or evolving questions. These priorities influence everything from storage choices to access patterns and governance models. Understanding these differences is essential before comparing costs or performance in isolation.
It is also important to recognise that these are conceptual models, not fixed products. Modern platforms increasingly blur the line between them. Warehouses support semi structured data. Data lakes add performance layers and query engines. These developments sit within a broader set of enterprise architecture patterns, which EmporionSoft explores in detail in its guide to enterprise architecture patterns.
For growing businesses, the key is not to memorise definitions, but to understand intent. A data warehouse answers questions you already know you need to ask. A data lake helps you ask questions you have not yet defined. Both can coexist, but only if their roles are clearly understood.
Industry guidance from platforms such as Microsoft’s data architecture framework reinforces this distinction by framing data lakes and warehouses as complementary components rather than competing endpoints. With this foundation in place, it becomes easier to examine how structural differences affect cost, performance, and risk as organisations scale.
Structural Differences That Shape Cost, Performance, and Risk
Once the conceptual differences between data lakes and data warehouses are clear, the next step is to examine how those differences play out in practice. Architecture decisions directly influence cost profiles, system performance, and operational risk. For growing businesses, these factors are often more important than feature checklists.
One of the most significant structural differences lies in how data is processed before storage. Data warehouses typically rely on ETL workflows. Data is cleaned, normalised, and structured before it is loaded. This upfront transformation improves query performance and data consistency, but it also increases development effort. Every new data source or reporting requirement may require pipeline changes, which can slow teams down as complexity grows.
Data lakes usually follow an ELT pattern. Raw data is loaded first, and transformation happens later when data is queried or processed. This reduces ingestion friction and allows teams to store large volumes of data cheaply. It also supports experimentation, since analysts and engineers can reshape data without rebuilding pipelines. The trade off is that transformation costs shift to query time, which can affect performance if workloads are not well managed. A deeper discussion of how architectural choices influence long term efficiency can be found in EmporionSoft’s perspective on cloud cost optimisation.
Storage economics further separate the two approaches. Data lakes are commonly built on low cost object storage, which scales horizontally and charges primarily for capacity. This makes them attractive for high volume and unstructured data. Data warehouses, especially those optimised for analytics, tend to use more expensive storage coupled with compute resources tuned for fast querying. While warehouses can be cost effective for well defined workloads, costs can escalate as data volumes and concurrent users increase.
Performance characteristics also differ in predictable ways. Data warehouses excel at structured queries and aggregations. Business intelligence tools benefit from predictable response times and optimised indexes. Data lakes, by contrast, prioritise throughput and flexibility over raw query speed. Performance depends heavily on the query engine, data format, and transformation strategy. This variability introduces risk if performance expectations are not aligned with use cases. EmporionSoft often addresses this alignment challenge when helping teams measure value using technology ROI metrics.
Scalability is another area where structural choices matter. Data lakes scale naturally with storage growth, making them suitable for long term data retention and analytics at scale. Data warehouses scale well for compute intensive workloads but may require careful capacity planning to avoid cost spikes. For growing organisations, the risk is committing too early to an architecture that optimises for current needs but constrains future growth.
These tensions have led to hybrid approaches, including the emergence of the data lakehouse concept. Lakehouse architectures attempt to combine low cost storage with warehouse like performance and governance. While promising, they introduce additional layers of complexity that teams must be prepared to manage. An overview of this direction is provided in Databricks’ explanation of the data lakehouse model.
Ultimately, structural differences are not just technical details. They shape how quickly teams can respond to change, how predictable costs remain over time, and how much operational risk a business absorbs. Understanding these impacts allows leaders to evaluate data lake vs data warehouse performance and cost trade offs in a way that supports sustainable growth rather than short term optimisation.
Governance, Security, and Operational Trade Offs
As data volumes grow and access broadens across teams, governance and security move from background concerns to operational priorities. The choice between data lakes and data warehouses has a direct impact on how easily an organisation can control data quality, manage risk, and meet regulatory expectations.
Data warehouses have traditionally been stronger in this area. Their schema on write approach enforces structure before data is made available for analysis. This makes it easier to define ownership, apply validation rules, and ensure consistent definitions across reports. Access controls are often tightly integrated, which supports role based permissions and auditability. For finance, compliance, and executive reporting, these characteristics reduce operational risk and support trust in the data.
However, this control comes at a cost. Governance processes in warehouses tend to be centralised and slower to adapt. As new data sources emerge, teams may wait weeks for approval, modelling, and pipeline updates. For growing businesses, this can create friction between governance requirements and the need for speed. Over time, teams may work around these constraints, introducing shadow systems that undermine the very controls the warehouse was meant to enforce.
Data lakes invert this balance. By design, they lower the barrier to ingestion and access. Teams can capture data quickly and explore it without waiting for formal modelling. This flexibility supports innovation, but it also increases governance challenges. Without clear standards, data lakes risk becoming fragmented collections of poorly documented datasets. Inconsistent naming, missing metadata, and unclear ownership make it difficult to answer basic questions about data lineage and reliability.
Security considerations follow a similar pattern. Data lakes often store sensitive and non sensitive data side by side, increasing the importance of strong access controls and classification. Misconfigured permissions or unclear policies can expose organisations to compliance and privacy risks. This is particularly relevant for SMEs operating across jurisdictions with different regulatory requirements. EmporionSoft addresses these concerns in its broader work on data privacy frameworks, where governance is treated as an architectural concern rather than a checklist exercise.
Operationally, the burden of governance shifts depending on the architecture. Warehouses concentrate effort upfront through modelling and validation. Data lakes distribute effort over time through metadata management, monitoring, and data quality tooling. Neither approach eliminates governance work. They simply change when and where it occurs.
Modern platforms attempt to bridge this gap by adding governance layers on top of data lakes, including catalogues, access policies, and quality checks. While these tools improve control, they also add complexity and require organisational discipline to be effective. Without clear ownership and processes, tooling alone cannot compensate for weak governance practices.
Industry guidance reinforces this perspective. For example, IBM’s overview of data governance emphasises that technology choices must be paired with operating models that define responsibility and accountability. This applies equally to data lakes and data warehouses.
For growing businesses, the governance question is not which architecture is safer by default. It is which model aligns better with the organisation’s current maturity and its ability to enforce standards consistently. Making this assessment early helps avoid costly rework and reduces the risk of data becoming a liability rather than an asset.
Use Cases That Matter for Startups and SMEs
For growing organisations, the value of any data platform is determined less by its technical elegance and more by how well it supports real business decisions. Abstract comparisons between data lakes and data warehouses only become meaningful when mapped to concrete use cases that startups and SMEs actually face.
Data warehouses are typically strongest in scenarios where questions are known in advance and answers must be trusted across the organisation. Executive dashboards, financial reporting, sales performance tracking, and regulatory reporting all benefit from a stable data model and consistent definitions. In these contexts, predictability matters more than flexibility. Business users expect fast, reliable answers, and discrepancies can erode confidence quickly. This is why data warehouses remain central to business intelligence workflows, particularly as organisations formalise decision making and reporting structures.
For many SMEs, the warehouse also becomes a shared language across departments. Marketing, finance, and operations work from the same metrics, reducing friction and debate. This alignment is especially valuable as teams scale and informal communication breaks down. EmporionSoft often sees this pattern when advising clients on system design trade offs, similar to those discussed in custom CRM vs SaaS decision making, where consistency and control are key considerations.
Data lakes, by contrast, excel when the questions are still evolving. Product analytics, customer behaviour analysis, experimentation, and machine learning initiatives often require access to raw, high volume data. Startups building data driven products or SMEs exploring AI capabilities benefit from the ability to ingest diverse data sources without heavy upfront modelling. This makes data lakes well suited to big data analytics and advanced use cases where exploration precedes standardisation.
Machine learning is a common example. Training models requires historical data in its most complete form. Transforming and aggregating data too early can remove signals that later become important. A data lake allows teams to preserve this richness while iterating on features and models. This aligns with the staged approach many organisations take when developing AI capabilities, as outlined in EmporionSoft’s AI roadmap for small businesses.
There are also hybrid use cases where both platforms play a role. An e commerce business might use a data lake to capture clickstream data and customer interactions, while relying on a data warehouse for revenue reporting and inventory analytics. In this setup, the lake supports experimentation and insight generation, and the warehouse supports operational decision making. The challenge is ensuring that data flows between the two are intentional and well governed.
Real world examples reinforce this distinction. Data lake implementations are common in organisations that prioritise product analytics, real time monitoring, or AI driven features. Data warehouse implementations are more prevalent where compliance, auditability, and repeatable reporting are critical. Both patterns appear across EmporionSoft’s case studies, depending on the client’s growth stage and strategic focus.
External guidance echoes these observations. Google’s reference architecture for analytics highlights how warehouses support structured reporting, while data lakes enable broader analytical workloads across diverse data types, as described in Google Cloud’s data warehouse architecture overview.
For startups and SMEs, the most important takeaway is that use cases evolve. A platform that fits today’s needs may struggle tomorrow if it cannot adapt. Evaluating data lake vs warehouse use cases through the lens of near term priorities and long term ambition helps ensure that data investments remain aligned with business reality rather than technological fashion.
Architecture Patterns and Modern Hybrid Approaches
As data needs become more diverse, many organisations find that a strict choice between a data lake and a data warehouse no longer reflects reality. Instead, modern architectures blend elements of both, aiming to balance flexibility, performance, and governance. Understanding these patterns is essential for growing businesses that want to avoid repeated platform migrations as requirements evolve.
Historically, architectures were simpler. Operational systems fed a central data warehouse, which powered reporting and dashboards. This pattern aligned well with structured data and predictable analytics. As new data sources emerged, especially unstructured and high volume streams, data lakes were introduced alongside warehouses rather than replacing them. The result was a layered architecture where each component served a specific purpose.
In this hybrid model, the data lake acts as a landing zone for raw and semi structured data. It absorbs change easily, supports large scale storage, and enables advanced analytics. The data warehouse remains the curated layer, optimised for trusted reporting and business intelligence. Data flows from the lake into the warehouse once it is cleaned, modelled, and aligned with business definitions. This approach reduces pressure on the warehouse while preserving governance where it matters most.
Cloud platforms have accelerated this convergence. Managed services now blur traditional boundaries by supporting semi structured data, external table access, and elastic compute. This has led to the emergence of the data lakehouse concept, which aims to provide warehouse like performance and governance on top of lake storage. Proponents argue that this reduces duplication and simplifies architecture, but the operational reality is more nuanced.
Lakehouse architectures introduce additional layers for metadata management, transaction handling, and performance optimisation. These layers can be powerful, but they also increase system complexity and skill requirements. For small teams, this can offset some of the promised efficiency gains. EmporionSoft often evaluates these trade offs through the lens of broader system design, similar to the considerations outlined in hybrid cloud strategies and distributed application models discussed in microservices vs serverless architectures.
Another architectural consideration is workload separation. Even within hybrid setups, separating analytical workloads by purpose can improve stability and cost control. For example, exploratory analytics and machine learning workloads can run against lake based storage, while executive reporting remains isolated on a warehouse optimised for consistent performance. This separation reduces the risk of one workload degrading another, a common concern as data usage scales.
From an enterprise architecture perspective, the key question is not which pattern is most modern, but which aligns with organisational capability. Introducing hybrid or lakehouse approaches requires clarity around data ownership, lifecycle management, and operational responsibility. Without this clarity, architectural sophistication can become a source of fragility rather than resilience. These alignment challenges are explored further in EmporionSoft’s discussion of enterprise architecture patterns.
External platform guidance reflects this cautious stance. Cloud providers emphasise that hybrid architectures should be driven by workload needs rather than ideology, as outlined in Databricks’ overview of the data lakehouse approach.
For growing businesses, modern data architecture is best seen as an evolving system. Hybrid approaches offer flexibility and future proofing, but only when matched with realistic assessments of team capacity and governance maturity.
Execution Considerations for Real World Teams
Even the most carefully chosen data architecture can fail if execution realities are ignored. For startups and SMEs, success with data lakes, data warehouses, or hybrid models depends less on theoretical fit and more on how well teams can operate, evolve, and sustain the system over time.
One of the first considerations is team capability. Data warehouses generally align well with traditional analytics skill sets. SQL proficiency, data modelling, and business intelligence tooling are widely available skills, making it easier to hire or upskill team members. This lowers execution risk in the short term. Data lakes, on the other hand, often require a broader mix of skills, including data engineering, distributed processing, and sometimes machine learning. For small teams, this can stretch capacity and increase reliance on a few key individuals.
Tooling choices also influence execution complexity. While there are extensive data lake tools and data warehouse tools available, selecting them without a clear operating model can lead to fragmentation. A common mistake is adopting multiple platforms to solve isolated problems, resulting in duplicated data and unclear ownership. EmporionSoft frequently encounters this pattern when reviewing systems affected by unmanaged growth and accumulated complexity, a challenge explored in technical debt and how to manage it.
Cloud infrastructure decisions introduce additional trade offs. Data lakes built on cloud object storage offer attractive entry costs, but they shift responsibility for optimisation and monitoring onto the team. Poorly tuned queries or uncontrolled experimentation can quickly drive up compute costs. Data warehouses abstract much of this complexity, but at the expense of less granular control. Understanding these dynamics is essential when planning cloud storage for data lakes or evaluating warehouse query optimisation strategies.
Operational processes matter as much as platforms. Clear data ownership, documented ingestion standards, and agreed quality thresholds help prevent confusion as more users access data. Without these practices, teams spend increasing time reconciling numbers rather than generating insight. This operational drag is often invisible at first, but it compounds as the organisation grows. EmporionSoft addresses these execution risks through its broader services offering, where architecture and operating models are designed together rather than in isolation.
Real world examples illustrate the importance of staged adoption. Many successful implementations begin with a focused warehouse for core reporting, then introduce a data lake to support specific analytical or product driven needs. Others start with a lake to capture raw data and later formalise reporting through curated warehouse layers. In both cases, incremental delivery reduces risk and allows teams to build confidence before expanding scope.
External guidance reinforces this pragmatic approach. Cloud providers such as Microsoft emphasise aligning data platform choices with team maturity and operational readiness, rather than defaulting to the most flexible option, as outlined in Microsoft’s data and analytics guidance.
For growing businesses, the execution question ultimately shapes when to use a data lake vs a warehouse. A platform that cannot be operated effectively will not deliver value, regardless of its theoretical advantages. Matching architecture ambition with team capability is therefore one of the most important decisions leaders can make as they scale their data foundations.
Making the Right Strategic Choice for Long Term Growth
By the time organisations reach the point of comparing data lakes vs data warehouses, the underlying question is rarely about technology alone. It is about how data supports growth, decision making, and resilience over time. There is no universally correct choice, only architectures that are more or less aligned with a business’s current reality and future direction.
For most growing businesses, the decision starts with clarity on intent. Data warehouses are well suited to environments where consistency, trust, and repeatable insight are critical. They support leadership reporting, financial oversight, and operational control, all of which become more important as organisations scale. When growth introduces more stakeholders and regulatory exposure, the predictability of a warehouse can reduce risk and friction.
Data lakes offer a different kind of strategic value. They create space for exploration, experimentation, and innovation. For companies building data driven products, investing in AI, or working with large volumes of diverse data, a lake provides flexibility that structured systems struggle to match. This flexibility can be a competitive advantage, but only if the organisation is prepared to manage the associated governance and operational complexity.
In practice, many businesses benefit from combining these approaches rather than choosing between them. A common long term pattern is to treat the data lake as a foundation for raw and evolving data, while using the data warehouse as a curated layer for trusted analytics. This hybrid model allows organisations to scale analytically without sacrificing control. The challenge lies in defining clear boundaries and data flows so that complexity does not grow unchecked.
Scalability is another strategic consideration. Early decisions tend to persist longer than expected, especially once data volumes grow and teams build dependencies. An architecture that scales technically but not organisationally can become a bottleneck. Conversely, a system that supports current reporting needs but cannot adapt to new analytical demands may force disruptive migrations later. Evaluating data lake vs warehouse scalability therefore requires looking beyond storage limits and considering people, process, and cost trajectories.
AI and advanced analytics further sharpen this choice. Even organisations that are cautious about adopting AI today are laying the groundwork for tomorrow. Access to historical, high fidelity data is a prerequisite for most machine learning use cases. This is why many leaders are reassessing how their data foundations support future experimentation, a theme that also appears in external perspectives on technical readiness such as TheCodeV’s guidance on technical due diligence for startups.
At EmporionSoft, these decisions are framed as part of a broader technology strategy rather than isolated platform selections. Our experience working with SMEs and scaling teams shows that the most successful outcomes come from aligning data architecture with business goals, team capability, and realistic growth plans. This alignment is explored further through our approach to long term system design and advisory work outlined on the EmporionSoft about page and our consultative engagements via technology consultation services.
Ultimately, choosing between data lakes and data warehouses is less about picking a winner and more about designing a system that can evolve. Organisations that invest the time to understand their data needs today, while planning for the uncertainty of tomorrow, are better positioned to turn data into a durable strategic asset rather than an operational burden.